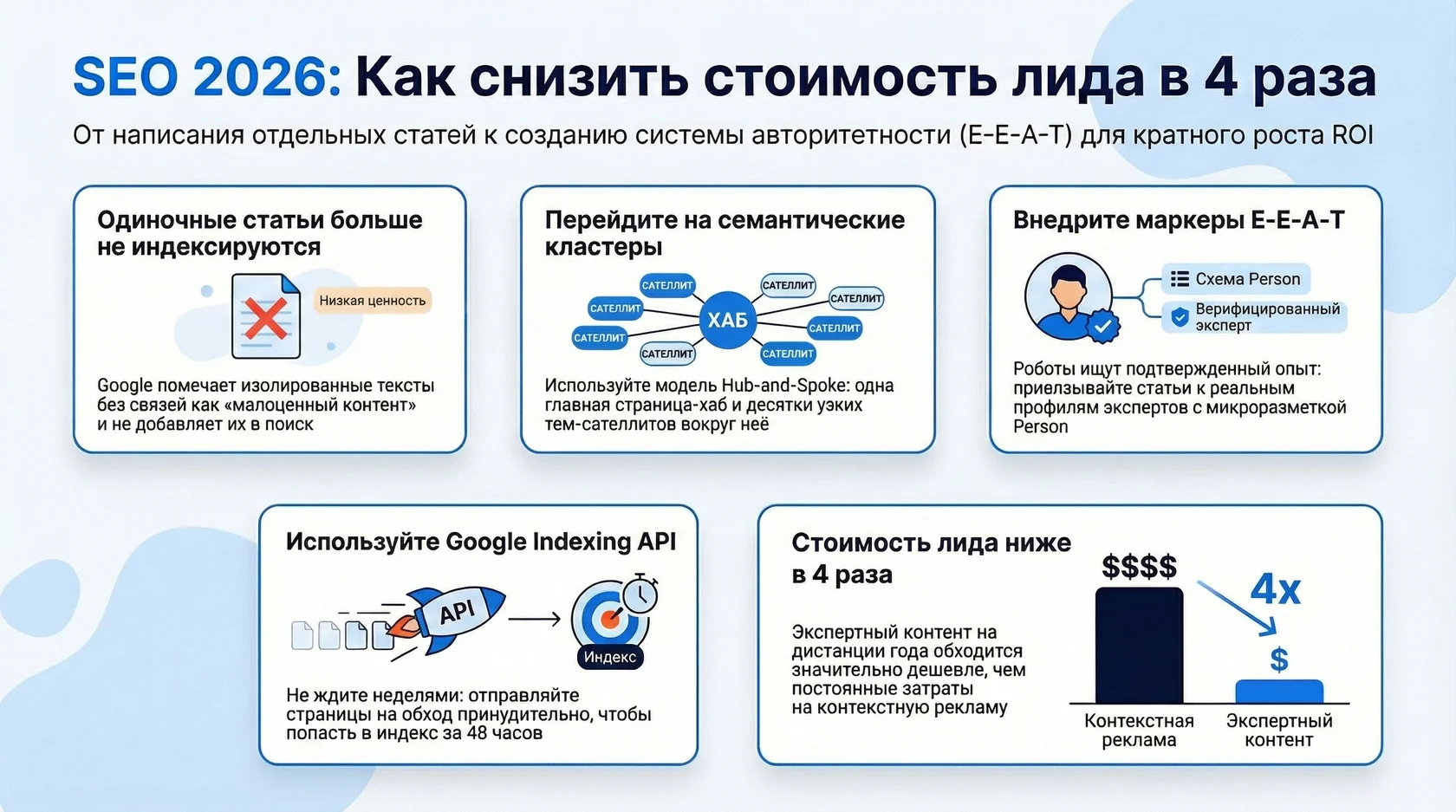
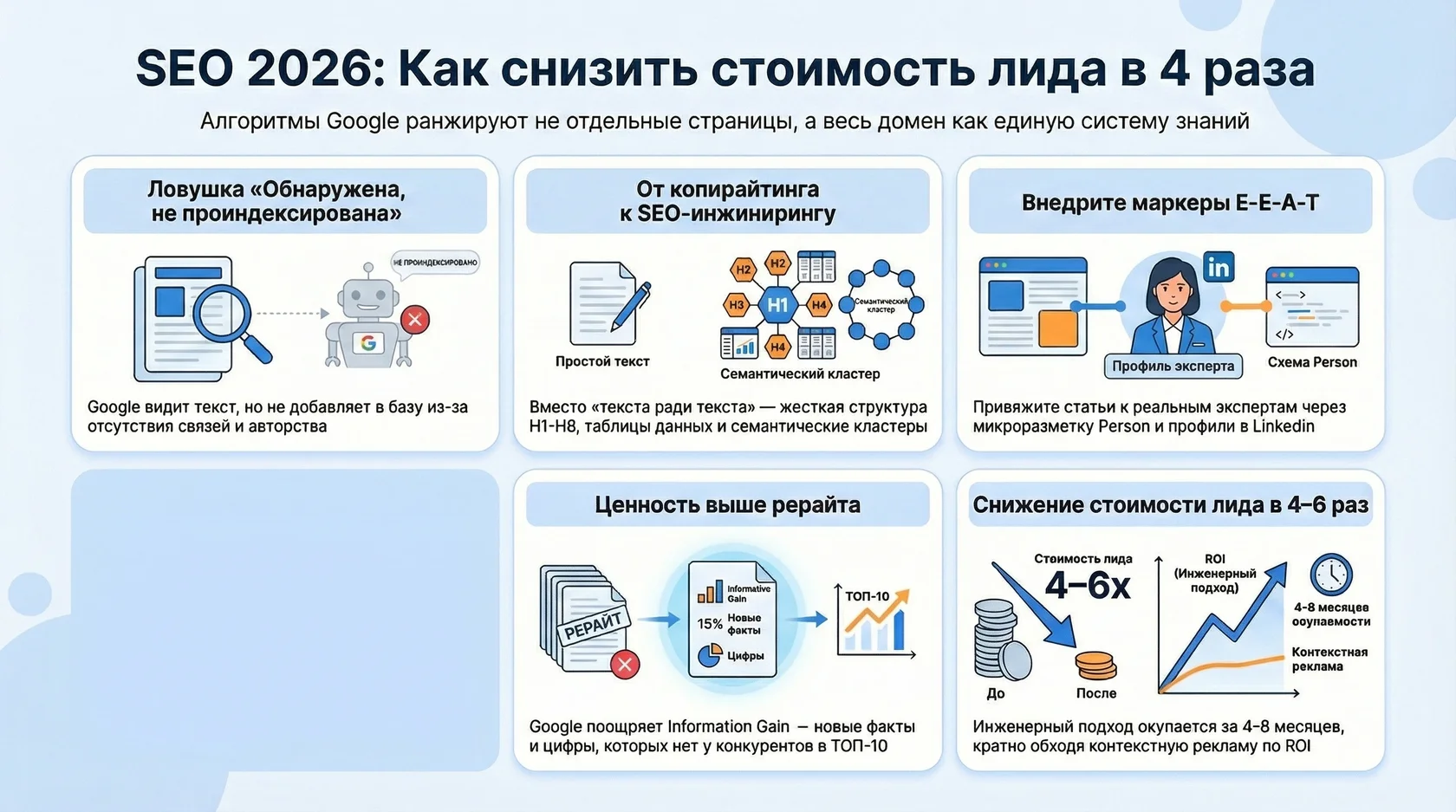
Владельцы B2B-компаний ежемесячно тратят бюджеты на написание текстов, опираясь на личный опыт или знания штатных специалистов. Результат всегда предсказуем: в панели Google Search Console появляется статус "Обнаружена, не проиндексирована". Поисковик видит текст, сканирует его, но отказывается добавлять в базу. Причина: алгоритмы Google образца 2026 года игнорируют изолированные тексты без подтвержденной архитектуры авторитетности. Чтобы получать органический трафик, нужно перестать генерировать слова и начать строить семантические кластеры, подтверждающие опыт, экспертность, авторитетность и достоверность (E-E-A-T). Главная сущность текущего SEO: алгоритмы ранжирования Google, которые оценивают не отдельный урл, а весь домен как единую систему знаний.
Ловушка экспертности: почему личного опыта недостаточно
Бизнес часто живет в парадигме начала десятых годов. Руководители заводов или дистрибьюторских центров уверены: если инженер напишет подробную инструкцию по эксплуатации промышленного насоса, поисковик автоматически поставит ее на первое место. На практике происходит другое: материал зависает в серой зоне краулингового бюджета.
Поисковая система сталкивается с миллиардами новых страниц ежедневно. Выделять вычислительные мощности на ранжирование одиночной статьи, которая не встроена в общую иерархию сайта, экономически невыгодно. Текст получает метку "малоценный контент" не из-за плохой грамматики, а из-за отсутствия связей. Если домен продает металлопрокат, но внезапно публикует статью про бухгалтерский учет на производстве без ссылок на профили авторов-аудиторов, Google классифицирует это как спам-сигнал.
Юнит-экономика производства контента складывается из времени профильного инженера, редактора и контент-менеджера. В приведённом расчёте один лонгрид стоит 80 000 ₸, десять материалов - 800 000 ₸. Если статьи остаются вне индекса и не приводят заявок, весь бюджет остаётся расходом. ROI рассчитывают по формуле: (доход, полученный благодаря контенту - расходы на контент) / расходы на контент × 100%. Для расчёта нужны источник сделки и выручка из CRM.
Эволюция алгоритмов: от плотности слов к графам знаний
Чтобы понять логику фильтрации, необходимо проследить хронологию изменения архитектуры поиска. Алгоритмы не усложнялись ради усложнения, они адаптировались под рост спама и развитие нейросетей.
2011-2014: борьба за качество (Panda и Penguin)
Эпоха доминирования ссылок и текстовых портянок закончилась с внедрением фильтров Panda и Penguin. Первый пессимизировал домены за переспам ключевыми фразами и ворованный текст, второй наказывал за покупку некачественной ссылочной массы. Базовое требование того времени: текст должен читаться человеком, а ссылки должны появляться естественным путем. Именно тогда бизнес усвоил правило писать "для людей", которое сегодня стало недостаточным.
2015-2019: внедрение ИИ (RankBrain и BERT)
В этот период произошел сдвиг от лексического поиска к семантическому. Алгоритм RankBrain начал использовать машинное обучение для понимания контекста запросов, с которыми система ранее не сталкивалась. Появление BERT (Bidirectional Encoder Representations from Transformers) позволило поисковику анализировать предлоги, союзы и порядок слов, улавливая скрытый интент. Google перестал искать точное совпадение фразы "купить трубы Астана" и начал искать страницы, способные удовлетворить потребность b2b-закупщика: прайс-листы, спецификации, условия доставки.
2020-2024: эпоха E-E-A-T и Helpful Content
Критическая точка для информационного маркетинга. Обновление Helpful Content Update (HCU) интегрировало классификатор на уровне всего сайта. Если 70% страниц ресурса признаются бесполезными, пессимизируются даже те 30%, которые написаны идеально. Одновременно с этим концепция E-A-T расширилась до E-E-A-T: добавился фактор Experience (личный опыт). Теперь недостаточно сослаться на энциклопедию, нужно доказать: автор держал товар в руках, тестировал софт или лично настраивал оборудование.
2025-2026: SGE и жесткая экономия краулингового бюджета
Текущая реальность диктуется развитием Search Generative Experience (SGE) или нейроответов. Поисковик сам синтезирует ответ на основе 3-4 самых трастовых источников. Попадание в индекс усложнилось кратно. Google экономит серверные ресурсы: краулер обходит новые урлы, но отправляет их в индекс только при наличии мощных сигналов авторитетности домена (Topical Authority). Текст без таблиц, видео, микроразметки авторов и четкой структуры H2-H3 отбраковывается на этапе пре-индексации.
Почему статьи не индексируются: технические и смысловые барьеры
Статус "Обнаружена, не проиндексирована" - это диагноз отсутствия контент-стратегии. Система фиксирует наличие контента, но не видит причин показывать его пользователям. Разберем механику отказа. Первая причина: вторичность информации (Information Gain = 0). Большинство копирайтеров работают по методу рерайтинга ТОП-10 выдачи. Они собирают три первые статьи и компилируют из них четвертую. Google легко распознает отсутствие новых фактов, цифр или сущностей. Если страница не добавляет новой ценности в мировой граф знаний, ее добавление в индекс математически бессмысленно.
Вторая причина: размытие тематического авторитета (Topical Authority). Если завод по производству ЖБИ-изделий начинает писать статьи про тайм-менеджмент для строителей, поисковик фиксирует диссонанс. Семантическое ядро должно строиться в виде плотного кластера (Hub-and-Spoke). Центральная страница описывает фундаментные блоки, а десятки сателлитов раскрывают узкие вопросы: марки бетона, морозостойкость, логистику негабаритных грузов.
Третья причина: непопадание в интент. Запрос "сертификация оборудования рк" может иметь информационный или транзакционный характер. Если пользователь ищет пошаговую инструкцию (Adilet регламентирует этот процесс строго), а вы предлагаете ему страницу услуги с кнопкой "заказать звонок" и одним абзацем текста, поведенческие факторы будут нулевыми. Алгоритм зафиксирует быстрый возврат в выдачу (pogo-sticking) и понизит позиции ресурса.
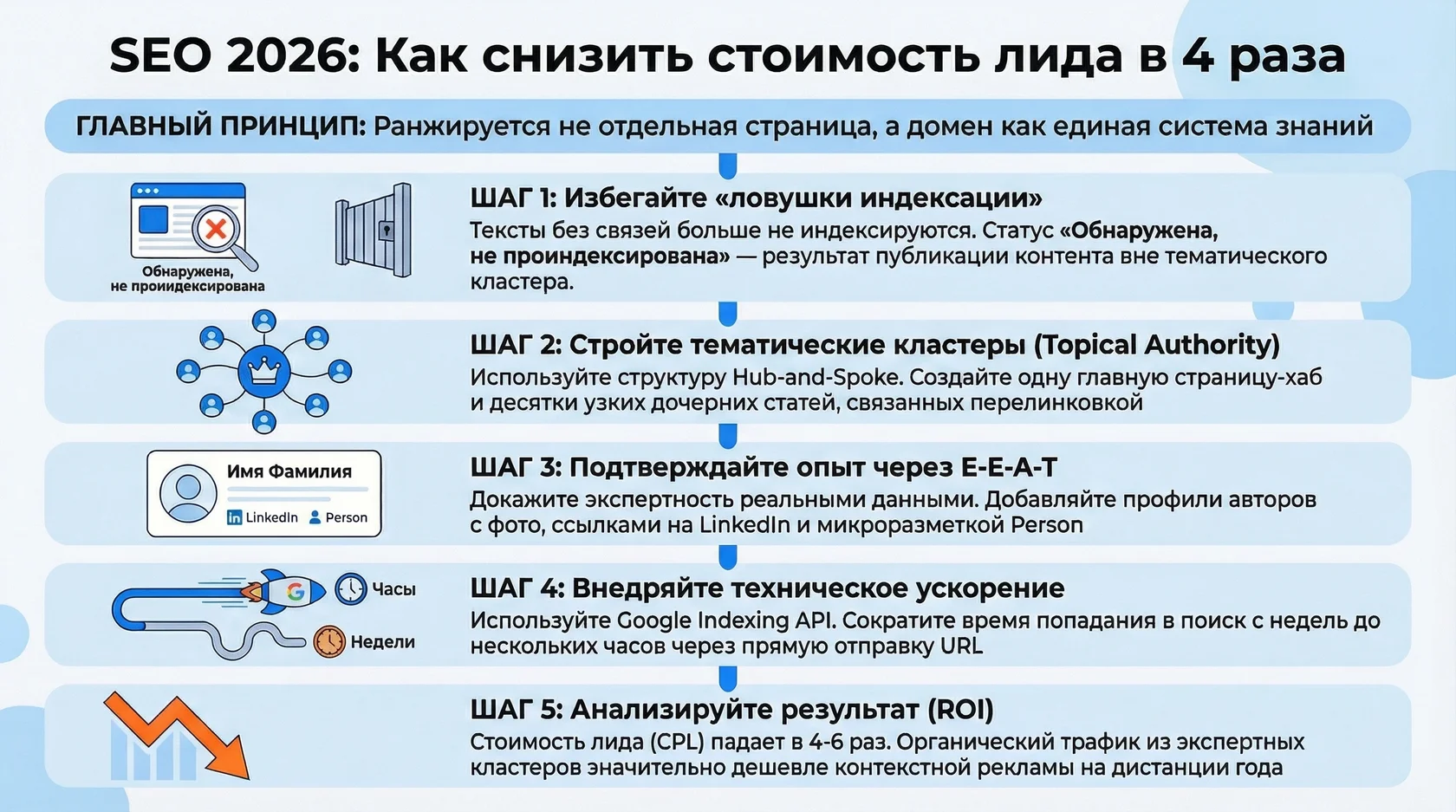
Пошаговое руководство: как вывести статью в ТОП выдачи
Создание материала, который пройдет фильтры E-E-A-T и попадет в блок нейроответов, требует инженерного подхода. Мы внедряем следующий алгоритм работы с информационными кластерами.
Шаг 1. Глубокий аудит интента и сбор сущностей
До написания первого символа необходимо выгрузить поисковую выдачу по целевому запросу. Задача: определить формат, который требует Google. Это может быть лонгрид, пошаговый чеклист, таблица сравнения или видеоинструкция. Выделяется главная сущность (Primary Entity) и строится список поддерживающих терминов, которые обязательно должны присутствовать в тексте. Инструменты: парсинг LSI-фраз, анализ графа знаний, сбор подвопросов (People Also Ask).
Шаг 2. Проектирование Topical Map
Страница не существует в вакууме. Перед ее созданием рисуется карта кластера. Главный хаб (Pillar Page) собирает высокочастотный трафик. От него идут внутренние ссылки на узкие темы (Cluster Content). Такая архитектура распределяет ссылочный вес и доказывает поисковику, что вы эксперт во всех нюансах ниши, а не только по верхам.
Шаг 3. Жесткая структура H1-H6
Скелет материала формируется исключительно на основе суб-интентов. Никаких введений об истории вопроса, если пользователь ищет инструкцию по ремонту. Требования к структуре:
- первый экран сразу дает ответ или таблицу с решением
- заголовки H2 содержат конкретную пользу, а не абстракции
- заголовки H3 раскрывают технические детали и микро-шаги
Шаг 4. Интеграция локальных и профильных фактов
Текст насыщается жесткими данными. Вместо абстрактного "оборудование должно соответствовать стандартам" пишется конкретика: "согласно техническому регламенту Таможенного союза ТР ТС 010/2011, насосные станции для нефтегазового сектора в Атырауской области подлежат обязательной сертификации". Использование точной терминологии создает ту самую добавочную ценность (Information Gain).
Шаг 5. Оформление E-E-A-T маркеров
Статья обязана иметь автора. Это не абстрактный "администратор", а реальный сотрудник компании с заполненным профилем. Чек-лист профиля автора:
- реальное фото и должность
- ссылки на профили в LinkedIn или профессиональные сети
- краткая биография, подтверждающая квалификацию (например: стаж 15 лет в логистике КНР-РК)
- микроразметка Person, связанная с организацией через атрибут worksFor
Шаг 6. Мультимодальность и визуализация
Сплошной текст не ранжируется. Для сложных концепций создаются схемы, алгоритмы работы, графики окупаемости. Каждое изображение сопровождается тегом alt, описывающим суть происходящего. Внедряются таблицы сравнения с помощью HTML, которые легко парсятся алгоритмами Google для формирования сниппетов (Featured Snippets).
Шаг 7. Техническая разметка JSON-LD
Поисковым роботам сложно читать неструктурированный HTML. Мы оборачиваем контент в жесткие схемы Schema.org. Для статей используется тип Article или TechArticle, для ответов на вопросы - FAQPage. Это прямой сигнал для робота о структуре данных на странице, что ускоряет обработку в разы.
Шаг 8. Оптимизация скорости и Core Web Vitals
Тяжелые скрипты, медленная загрузка картинок, сдвиг макета при рендеринге (CLS) - прямые причины отказа в индексации мобильной версии. Статья должна быстро загружаться при слабом мобильном сигнале. Настраивается отложенная загрузка изображений (lazy loading), минифицируются стили.
Шаг 9. Запрос на повторный обход через Google Search Console
После публикации проверьте страницу в инструменте проверки URL Google Search Console и отправьте запрос на индексирование. Добавьте URL в sitemap.xml и поставьте внутренние ссылки с уже проиндексированных страниц сайта. Эти действия помогают Google быстрее обнаружить материал, но срок повторного обхода и добавления в индекс определяет поисковая система.
Специфика SEO-продвижения на рынке Казахстана
Локальное гео диктует свои правила игры в поиске. Копирование стратегий других рынков без адаптации ведет к сливу бюджета.
Двуязычие - ключевой фактор. Доля поисковых запросов на казахском языке стабильно растет. Это не означает бездумный машинный перевод. Для высококонкурентных ниш (медицина, финансы, авто) требуется создание полноценной языковой версии сайта (через подпапки /kz/ или субдомены) с учетом морфологии и интентов казахоязычной аудитории.
Региональность имеет критическое значение в B2B. Алматы генерирует спрос на услуги, IT, консалтинг. Атырау и Актау - центр нефтегазового сектора и сложной логистики. Шымкент - производство, сельское хозяйство и ритейл. Статья, нацеленная на продажу спецтехники, должна учитывать логистические маршруты и таможенные посты конкретного региона.
Изменение потребительского поведения. Информационный спрос все чаще пересекается с маркетплейсами. Пользователь ищет "кабель ввгнг технические характеристики", чтобы потом проверить цену в приложении Kaspi. Контент-стратегия должна учитывать этот путь пользователя: статья должна подогревать интерес и переводить трафик в лидогенерационную форму или каталог до того, как клиент уйдет сравнивать цены на сторонние площадки.
Сравнение подходов к созданию контента
| Параметр | Классический копирайтинг (Фриланс/Штат) | SEO-инжиниринг контента (E-E-A-T) |
|---|---|---|
| Анализ интента | Отсутствует. Текст пишется по прямому ТЗ. | Сбор семантики, LSI, анализ конкурентов в ТОП-10, определение формата ответа. |
| Структура и глубина | Вода, длинные вступления, переписывание чужих статей. | Жесткая иерархия H1-H6, таблицы, списки, расчеты юнит-экономики, локальные факты. |
| Авторитетность (E-A-T) | Автор не указан или указан "Админ". | Привязка к профилю эксперта, микроразметка Person, указание регалий и опыта. |
| Техническая оптимизация | Сдача в Word или Google Docs. | Верстка HTML, микроразметка Article/FAQPage, оптимизация изображений, настройка перелинковки. |
| Результат в Google | "Обнаружена, не проиндексирована". Трафик 0. | Индексация в течение 48 часов. Ранжирование по низкочастотным кластерам, рост Topical Authority. |
Бюджетирование и сроки окупаемости
Создание группы экспертных материалов - инвестиция в SEO-раздел сайта. Стоимость включает анализ спроса, подготовку, редактуру, верстку, техническую проверку и перелинковку, поэтому её нельзя сравнивать с ценой одного текста на бирже.
| Тариф / Объем работ | Состав услуги (спринт 1 месяц) | Средняя стоимость (₸) |
|---|---|---|
| Базовый кластер (Локальный B2B) | Аудит ниши, сбор семантики на 1 услугу. Написание 4 глубоких экспертных статей. Внедрение микроразметки, создание профиля автора. | от 450 000 ₸ |
| Topical Authority (Регион + Масштаб) | Сбор полного графа знаний. Написание 10 лонгридов (от 15к знаков). Полная HTML-верстка, таблицы, API-индексация, перелинковка Pillar-Cluster. | от 950 000 ₸ |
| Enterprise SEO (Мультиязычность) | Двуязычное ядро (RU/KZ). Разработка 20+ материалов в месяц. Интеграция с каталогом товаров, создание интерактивных калькуляторов, SGE-оптимизация. | от 1 500 000 ₸ |
Сроки окупаемости (ROI) в B2B-сегменте составляют от 4 до 8 месяцев. Контент начинает приносить целевой органический трафик, снижая зависимость от платных каналов привлечения (Яндекс Директ или Google Ads). Стоимость привлечения лида (CPL) через информационный поиск на дистанции года падает в 4-6 раз по сравнению с аукционом контекстной рекламы. Формула оценки рентабельности рассчитывается так: CPA=Количество органических лидов/Бюджет на контент
.
.
Критические ошибки и слив бюджета
Внедрение контент-стратегии сопровождается техническими рисками, которые обнуляют результат.
Игнорирование логов сервера. Многие публикуют материалы и ждут. Анализ серверных логов показывает, как часто Googlebot посещает новые урлы. Если бот заходит на страницу, но не скачивает HTML полностью (из-за таймаута сервера), индексации не будет.
Для запросов с меняющимися данными Google учитывает актуальность информации. Статья о налоговых ставках, написанная в 2023 году, к 2026 году может содержать устаревшие факты и терять доверие читателя. Поэтому такие материалы нужно регулярно проверять, обновлять данные и указывать дату последней проверки. Простая смена даты публикации без корректировки фактов задачу не решает.
Неправильная каннибализация запросов. Создание нескольких статей под один и тот же интент ("как выбрать компрессор" и "какой компрессор лучше купить"). Поисковик не понимает, какую страницу ранжировать выше, и в итоге пессимизирует обе. Каждая страница должна отвечать за строго определенный кластер семантики без пересечений.
Кейс: кратный рост органики для поставщика промышленного оборудования
Исходные данные: ТОО в Алматы, занимающееся поставками насосного оборудования для добывающего сектора. Запущено 40 информационных статей, написанных фрилансерами. Проблема: 35 из 40 статей имели статус "Обнаружена, не проиндексирована". Органический трафик в блог: 12 человек в месяц. Лидов: 0.
Наш опыт показывает, что исправление ситуации требует хирургического вмешательства в архитектуру. Этапы работ:
- Удаление 15 нерелевантных статей (про чистку бассейнов - нецелевой интент).
- Склейка 20 статей в 5 массивных лонгридов (Pillar pages) с редиректами 301.
- Добавление технической спецификации, схем подключения и реальных фотографий со складов в Алматы.
- Внедрение блока "Автор": главный инженер компании с указанием сертификатов.
- Настройка перелинковки с информационных хабов на карточки товаров.
Результат через 5 месяцев: проиндексировано 100% обновленных материалов. Трафик вырос до 450 целевых посетителей в месяц. Получено 8 квалифицированных заявок на расчет стоимости оборудования со средним чеком контракта 15 000 000 ₸. Инвестиции в SEO-инжиниринг окупились с первой сделки.
FAQ
Почему Google видит страницу, но не добавляет в индекс?
Поисковик оценивает рентабельность краулинга. Если страница дублирует существующий в сети контент, не имеет подтвержденного авторства (E-E-A-T) или не привязана к тематическому ядру сайта, алгоритм маркирует ее как малоценную и экономит серверные ресурсы на ее индексацию.
Как доказать экспертность автора для B2B-сайта?
Необходимо создать детальную страницу автора с реальным фото, должностью, биографией и ссылками на профессиональные соцсети. Обязательна интеграция микроразметки Schema.org типа Person, где атрибут worksFor жестко связывает автора с организацией (Organization).
Сколько времени занимает получение трафика с новых статей?
Срок добавления страницы в индекс определяет Google: после запроса на повторный обход процесс может занять от нескольких дней до нескольких недель. Для выхода в ТОП-10 по узким низкочастотным B2B-запросам можно закладывать от 3 до 6 недель, для высококонкурентных хабовых страниц - от 3 до 5 месяцев. Это плановые сроки без гарантии: результат зависит от конкуренции, качества материала и технического состояния сайта.
Нужно ли переводить статьи на казахский язык?
Для рынков ритейла, финансов, медицины и b2c-услуг - обязательно. В тяжелом B2B решение принимается на основе парсинга спроса. Если есть устойчивая частотность запросов на государственном языке (особенно в западных и южных регионах РК), создание отдельной языковой версии /kz/ с адаптацией интента кратно расширяет охват.
Как повлиять на выдачу AI Overviews в Google?
Нейросетевые ответы формируются из источников с максимальным трастом. Чтобы попасть в сниппет, текст должен содержать четкую структуру H2-H3, списки, HTML-таблицы с данными и не иметь воды. Google SGE вытягивает сухие факты, определения и цифры, игнорируя пространные рассуждения.
Можно ли использовать нейросети для написания SEO-текстов?
Генерация текста нейросетями без редактуры приводит к бану за спам. ИИ можно использовать для сбора структуры, парсинга LSI или перевода кода микроразметки. Итоговый материал должен проходить глубокую факт-чекинг модерацию, насыщаться локальными данными РК и реальным бизнес-опытом, который нейросеть не может сгенерировать.
Заключение
Инвестиции в производство контента без учета архитектуры авторитетности и новых алгоритмов поисковых систем - это прямые финансовые потери. Алгоритмы больше не ранжируют текст ради текста. Они оценивают графы знаний, факты, техническую оптимизацию и реальный опыт бизнеса. Выживает и забирает трафик тот, кто строит плотные семантические кластеры и работает с интентами, а не с плотностью ключевых слов.
Чтобы контент приводил заявки, обращайтесь в Метриум. Мы проанализируем спрос, подготовим Topical Map с темами и страницами, настроим перелинковку и будем оценивать результат по индексации, трафику и обращениям по направлениям Маркетинг под ключ и SEO-продвижение.
Еще больше полезных материалов по маркетингу и аналитике читайте в блоге агентства.