Индексация сайта в Google не техническая мелочь, это право на присутствие в поиске. Пока страница не вошла в индекс, её не существует для аудитории, и трафик уходит конкурентам. Для казахстанских компаний это вопрос денег и предсказуемости потока заявок: Google даёт основную долю поисковых визитов, скорость индексации определяет, когда новые услуги, категории и статьи начнут работать на спрос.
В этой статье владельцы сайтов, маркетологи, директора по развитию смогут узнать причины, из-за которых страницы застревают вне индекса, смогут просто настроить проверяемую диагностику через инструменты Google и получат по-шаговый план исправлений, сравнение рабочих подходов, ориентиры по срокам и риски. Так же поделимся своим опытом и сделаем короткий разбор кейса рынка услуг Алматы с цифрами, чтобы показать, как на практике технические решения превращаются в видимость и лиды.
Что это и зачем бизнесу в Казахстане
Почему индексация сайта в Google критична для дохода малого бизнеса в Казахстане?
Индексация - это включение страницы в поисковый индекс, откуда она может попасть в выдачу по релевантным запросам. Без индекса трафика не будет, а медленная индексация задерживает появление новых страниц услуг, каталога и контента.
Для рынка Казахстана это особенно заметно: по данным StatCounter за последние 12 месяцев Google удерживает около двух третей рынка поиска, конкурируя с Яндексом, что означает высокую зависимость бизнеса от того, как быстро и полно Google находит и включает страницы в индекс. Если новые страницы висят в статусах вроде Discovered или Crawled без индекса, сайт теряет показы по горячим запросам, а рекламные бюджеты вынужденно компенсируют органический недобор.
При этом индексация управляется не магией, а четкими техническими сигналами: доступность, отсутствие блокировок, консистентный каноникал, карта сайта с живыми URL, правильные ответы сервера, понятная связи между страницами и рендер контента, который видит бот. Когда эти составляющие выстроены системно, скорость попадания в индекс сокращается с недель до дней, а масштабируемость по разделам становится управляемой.
Пошаговый план ускорения индексации
С чего начать: как быстро проверить индексируемость без сюрпризов?
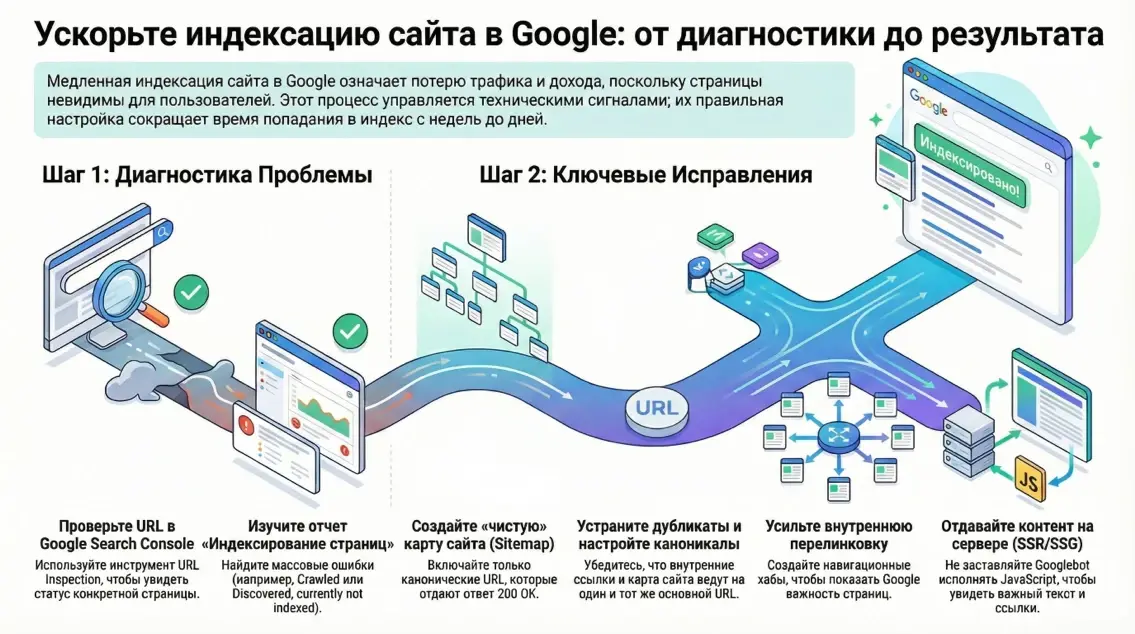
Базовая диагностика начинается с Google Search Console. Инструмент URL Inspection показывает, видит ли система страницу, какую выбрала каноническую версию, как прошел рендер и нет ли запретов на индексирование. Далее открываем отчет Page indexing, где причины исключений собраны по кластерам: Discovered - currently not indexed, Crawled - currently not indexed, Duplicate without user-selected canonical, Soft 404, Excluded by noindex, Blocked by robots.txt, Redirect и прочие. На этом этапе важно зафиксировать объём проблем и их природу, а не гадать.
Для приоритетных страниц проверяем живую версию через Live test, чтобы исключить нестабильности контента, зависящие от рендера или ответов сервера. Если каноникал выбран другим, смотрим сигналы: внутренние ссылки, карту сайта, rel=canonical, hreflang и редиректы. Итог первого шага — список конкретных причин с примерами URL, чтобы перейти к исправлениям без абстрактных гипотез.
Как настроить robots.txt, чтобы случайно не закрыть важные разделы?
Robots.txt управляет краулингом, а не индексацией, но ошибки здесь блокируют обход и откладывают включение в индекс. Практика простая: не закрывать разделы с ценным контентом и не пытаться использовать robots.txt для удаления уже проиндексированных страниц.
Страницы, которые не должны появляться в выдаче, помечаются noindex или X-Robots-Tag на уровне заголовка ответа. В robots.txt логично указывать ссылку на карту сайта, чтобы бот стабильно находил свежие URL. Документ должен отвечать 200, быть легким и читаемым. Если файл отсутствует или отдаёт 404, Google может краулить сайт без ограничений, поэтому запреты следует формулировать явно, а не полагаться на несуществующий файл.
В спорных кейсах проще сузить проблему до группы путей и протестировать поведение через лог-анализ или повторные проверки страниц в URL Inspection, пока исключения не перестанут воспроизводиться.
Как собрать и отправить корректную карту сайта, чтобы бот быстрее нашёл нужные URL?
Карта сайта нужна для обнаружения URL, а не как гарантия индексации. Включайте только канонические, открытые к индексации страницы, возвращающие 200, без параметров, пагинации и дублей. Соблюдайте лимиты протокола: не более 50 000 URL и не более 50 МБ на файл, для больших сайтов разбивайте на индекс карт. Отправляйте sitemap в Search Console и дублируйте ссылку в robots.txt.
Следите за долей неиндексируемых адресов в карте: если туда попадают закрытые или редиректные URL, доверие к сигналу падает, а диагностика усложняется. Для ускорения по важным разделам разумно держать отдельные карты по типам страниц, чтобы видеть по отчётам, где именно индекс движется, а где застопорился. Регулярно обновляйте lastmod для реальных изменений, а не шумите лишними обновлениями, которые не влияют на содержание.
Как устранить дубликаты и выбрать канонические URL без конфликтов сигналов?
Дубликаты забирают краулинговые ресурсы и откладывают индексацию уникальных страниц. Консистентность важнее всего: единый вариант домена, HTTPS, единые слэши, параметры и сортировки. На каждой странице задавайте rel=canonical на саму себя, если это финальная версия.
Внутренние ссылки должны указывать на канонический путь, редиректы 301 должны поддерживать ту же логическую цель. Карта сайта содержит только канонические адреса. Если бот выбирает другой каноникал, значит сигналы противоречат друг другу: проверьте ссылочную структуру, hreflang, шаблон заголовков и близость контента по группам страниц. В спорных случаях лучше упростить архитектуру URL, чем годами спорить с алгоритмом.
Консистентность внутренних ссылок и карты сайта обычно разворачивает выбор каноникала в вашу пользу, после чего статус Duplicate постепенно исчезает.
Как сделать контент на JavaScript видимым без костылей и задержек индексации?
Главное правило простое: предоставляйте боту полноценный HTML, где ключевой контент и ссылки доступны без ожидания исполнения тяжелых скриптов. Динамический рендеринг признан временным обходным решением и больше не рекомендуется как стратегия, потому что усложняет инфраструктуру и порождает рассинхроны между ботом и пользователем.
Предпочтительны SSR или SSG в применяемом фреймворке с сохранением критического HTML на сервере. Проверяйте рендер через URL Inspection и журналы сервера, чтобы убедиться, что Googlebot получает тот же смысловой слой, что и пользователь. Если блоки зависят от API и появляются после событий на клиенте, вынесите текст и ссылки в базовый HTML. Это резко сокращает зависимость индексации от очередей рендера и снижает вероятность статусов вида Crawled без индекса.
Как ускорить краулинг за счет внутренней перелинковки и лог-аналитики?
Сильная связи между страницами подает сигнал важности разделов, помогает боту экономить переходы и ускоряет обнаружение новых страниц. Сетку ссылок стоит строить по иерархии и по тематическим кластерам, чтобы боту не приходилось угадывать маршруты. Журналы сервера показывают, где Googlebot ходит чаще, какие шаблоны страдают от задержек ответа и где отдаются нежелательные коды. Выделите хабы навигации и положите туда ссылки на новые материалы. Уберите лишние ссылки на фильтры, параметры и пагинацию, которые плодят дубликаты.
Поддерживайте свежие карты сайта для приоритетных кластеров, но не подменяйте ими архитектуру. Итогом должно стать сокращение среднего времени первого обхода по новым URL и заметное уменьшение доли страниц в статусах обнаружено или просмотрено без включения в индекс, особенно в сезонных разделах и блогах.
Сравнение альтернатив: плюсы и минусы
Что быстрее и безопаснее: карта сайта, URL Inspection или сторонние «индексаторы»?
Карта сайта обеспечивает надежное обнаружение, массово и без ручной рутины. URL Inspection полезен для точечных случаев, когда критично ускорить отдельные страницы и проверить рендер. Сторонние «индексаторы», имитирующие сигналы, не дают гарантий и создают технический шум, который не ускоряет реальные процессы Google.
На практике лучше сочетать корректные карты сайта по типам контента и разумное точечное использование URL Inspection для лидогенерирующих страниц и важных обновлений. При таком подходе скорость первой индексации держится в пределах нескольких дней, а дальнейшая переиндексация становится предсказуемой. Нагрузку на команду это снижает, а эффект устойчиво масштабируется вместе с ростом контента и разделов.
Стоит ли использовать Indexing API для обычных страниц?
Нет, если это не вакансии или прямые эфиры. Indexing API официально предназначен для JobPosting и BroadcastEvent, поэтому для обычных страниц он не подходит. Попытки обойти ограничения не дают устойчивого эффекта и несут операционные риски.
Для контентных сайтов, e-commerce и сервисных страниц используйте стандартные механики: карты сайта, четкую архитектуру, стабильные ответы сервера, консистентный каноникал и чистые журналы. Когда сигналов достаточно, индексация идет предсказуемо и без «хаков».
Цена и сроки: факторы и ориентиры
Сколько времени обычно уходит на индексацию и что ускоряет процесс без лишних трат?
Стартовые сроки по новым сайтам колеблются от нескольких дней до пары недель на первые кластеры URL, при условии корректной технической базы и карт сайта. Дальше скорость зависит от объема и качества контента, стабильности ответов сервера, внутренней перелинковки и отсутствия конфликтных сигналов по каноникалам и мета-директивам. Бюджет влияет через приоритет задач: аудит, исправление шаблонов, настройка SSR или упрощение JS, системная работа с журналами и устранение узких мест по шаблонам.
Быстрее всего окупаются исправления, влияющие сразу на сотни страниц: карты сайта по типам, каноникал, навигационные хабы, чистка robots.txt и резкое снижение доли неиндексируемых URL. Реалистичный ориентир для уже действующих сайтов после набора критической массы сигналов — первые индексации за дни, а переиндексации важных правок за часы или дни, в зависимости от веса раздела.
Ошибки и риски: как не сломать индексацию
Какие ошибки в robots.txt и мета-тегах чаще всего убивают индексацию и как их обнаружить?
Часто встречается блокировка через Disallow целых разделов вместе с CSS и JS, что мешает рендеру.
Вторая распространенная ошибка - noindex на шаблонах, который унаследовали важные страницы. Третья — конфликтные сигналы каноникала и внутренней перелинковки, когда карта сайта заявляет один адрес, а ссылки ведут на другой.
Еще один частый сценарий - неверные коды ответа: 200 на пустых страницах, цепочки 302, длительные 5xx или Soft 404, из-за чего бот откладывает включение в индекс. Чтобы не гадать, опирайтесь на отчеты Page indexing, выбор каноникала в URL Inspection и журналы веб-сервера.
Снимайте проблемы пакетно по шаблонам, проверяйте, что карта сайта перестала содержать закрытые или несуществующие URL, и убеждайтесь, что внутренняя навигация ведет на тот же канонический путь, который вы заявляете в разметке.
Почему появляется «Crawled - currently not indexed» и как вытащить страницы из этого состояния?
Этот статус значит, что бот прошел по странице, но не включил ее в индекс. Причины разные: слабый контент без явной ценности, дубли и тонкие вариации, слабые сигналы важности из-за перелинковки, технические проблемы рендера или медленные ответы сервера.
Рабочая схема выхода такая: сгруппируйте проблемные URL по шаблонам, уберите вариации без ценности, укрепите уникальность текстов и заголовков, приведите каноникал и внутренние ссылки к одному адресу, выведите важные страницы в хабы и карты сайта. Проверьте рендер через Live test, чтобы бот видел тот же контент, что и пользователь. Далее перезапрос индексации точечно для ключевых страниц и мониторинг по отчетам.
В результате часть страниц попадет в индекс быстро, а оставшиеся доберутся туда после накопления сигналов.
Кейс: индексируем новый сайт услуг в Алматы
Исходные данные: домен с нулевой историей, 30 страниц услуг и 20 материалов блога. Состояние на старте: карта сайта сливает все URL в один файл, часть страниц возвращает 200 с пустыми шаблонами, внутренние ссылки размазаны, навигационного хаба нет, SSR отсутствует, контент рендерится на клиенте.
План работ на 14 дней: в первый день включили отдельные карты сайта по типам, поправили robots.txt, создали хабы услуг и блога с ручной перелинковкой на приоритетные URL, привели rel=canonical к самоссылкам и вычистили редиректные адреса из карт.
На 3-5 день перевели критические шаблоны на SSR, вынесли текстовые блоки в HTML, проверили рендер через URL Inspection.
На 6-8 день устранили Soft 404 и пустые страницы, свернули параметры фильтров.
На 9-11 день усилили внутренние ссылки из статей на услуги, обновили lastmod только для реально измененных страниц.
На 12-14 день точечно запросили индексацию лидогенерирующих URL, проверили выбор каноникала и статусы в отчетах.
Результат: первая волна индексации услуг до конца первой недели, блоги начали попадать во вторую неделю, доля страниц в статусах Discovered и Crawled без индекса снизилась кратно, а новые материалы стали индексироваться за 1-3 дня при последующей публикации.
Основа успеха - консистентные сигналы, чистые карты сайта, SSR для ключевых шаблонов и дисциплина по внутренним ссылкам.
FAQ
Можно ли ускорить индексацию только картой сайта
Карта сайта помогает обнаружить URL, но не гарантирует включение в индекс. Важно, чтобы страницы были каноническими, открытыми и содержали полезный контент. Тогда карта сайта станет сильным сигналом для очереди обхода.
Имеет ли смысл массово жать «Request indexing» в URL Inspection
Это инструмент точечного действия для важных страниц и проверок рендера. Для масштабирования лучше чистые карты сайта, стабильные ответы сервера и сильная перелинковка, иначе ручные запросы дадут кратковременный эффект.
Можно ли использовать Indexing API для обычных статей и карточек услуг
Нет, API предназначен для JobPosting и BroadcastEvent страниц, поэтому для обычных страниц применяется стандартный процесс краулинга через карты сайта и ссылки.
Почему Google выбирает не тот каноникал, который я указал
Система учитывает множество сигналов. Если связи между страницами, карты сайта и редиректы противоречат rel=canonical, Google может выбрать другой URL. Выравнивайте все сигналы на один адрес.
Страницы на JavaScript плохо индексируются. Что делать
Отдавайте критический контент на сервере с SSR или SSG, не полагайтесь на отложенный рендер. Dynamic rendering считается временным обходным подходом и больше не рекомендуется.
Насколько важна индексация в Казахстане с учетом доли Яндекса
В Казахстане Google остается крупнейшим источником поиска, поэтому исправная и быстрая индексация в Google критична для стабильного потока органики даже при заметной доле Яндекса.
Заключение
Индексация - это управляемый процесс, где побеждают базовые дисциплины: доступность, консистентные каноникалы, чистые карты сайта, понятные хабы, стабильный сервер и рендер без сюрпризов.
Если сделать все это системно, сайт начинает индексироваться быстро, а переиндексации идут по предсказуемым циклам. Хотите надежный результат без лишнего шума, обращайтесь в маркетинговое агентство Метриум, мы выстроим технику и процессы под ваш бизнес в рамках наших услуг маркетинг под ключ и SEO-продвижение.
Еще больше полезных разборов и практик по SEO и маркетингу читайте в блоге Метриум.